May 24, 2026
Token count is the new headcount
We went from $200/month of AI subscriptions to $12,500/month of token spend in 3 months. Same speed in humans would be ~$125K/month payroll. Here's the math, the pattern, and why most companies will miss it.
TL;DR
- $1 of tokens ≈ $10 of human labor. This ratio has held stable across every model release.
- We went from $200/mo in AI subscriptions to $12,500/mo in real token value in 3 months.
- That’s the equivalent of a $125K/mo payroll — 10 devs, 1 assistant, 2 BD — without the headcount.
- The price of tokens isn’t what’s moving. The harness is — the system you build to convert tokens into work.
- In 12 months: Claude 5, GPT 6. Structure your org for what AI will do then, not what it does today.
The math
Three months ago: one Claude Max subscription at $200/mo. Today: two Claude Max subs + one OpenAI at $500/mo in subscription fees. But subscription fees aren’t the real number.
The real number is token consumption. Claude’s $200/mo plan delivers roughly $5,000 of API-equivalent value — Anthropic is pricing subscriptions at a loss to kill the competition. At current consumption, we’re burning through about $12,500/mo of real token value.
| Period | Subscriptions | Real token value | Human payroll equivalent |
|---|---|---|---|
| 3 months ago | $200/mo | ~$1,000/mo | ~$10K/mo |
| Today | $500/mo | ~$12,500/mo | ~$125K/mo |
| 12 months out (projected) | $1,000/mo | ~$50,000/mo | ~$500K/mo |
$1 of tokens ≈ $10 of human labor. That ratio has been stable for 18 months across every model generation.
The cost of tokens will rise as Anthropic and OpenAI stop burning investor capital on discounted subscriptions. But the work-per-token ratio holds — better models do more useful work per token, not just more tokens. What changes the output isn’t the token price. It’s how many tokens you can usefully consume.
What’s actually moving: the harness, not the price
The harness is the system you build around AI to convert tokens into useful work.
Think of it as a solar panel. The sun (token supply, model capability) keeps getting stronger. What limits your output is how much of it your panel can capture.
A year ago, I could consume about $10 of tokens per day. AI was dumb enough that it would change a button color and then stall — I’d have to re-prompt, correct, re-explain. Most of the session was friction. Now I consume ~$500/day personally. The autonomous agents running in the background add another ~$50/day without me touching anything.
- One year ago: ~$10/day (high friction, narrow tasks, constant re-prompting)
- Six months ago: ~$100/day (more task types, less hand-holding)
- Today: ~$500/day me + ~$50/day autonomous agents
We’re probably using 10% of what’s actually available to us today.
The harness improves every 2–3 months when new models drop. The next meaningful jump is June/July with Claude’s next release. The teams that will be ahead of the market in January 2027 are the ones building harness capacity now, not the ones waiting to see what the models can do. See the OpenClaw setup guide for how I run the infrastructure layer.
The supervise → skill loop
This is how you build harness in practice. It works on every AI tool; what varies is the harness layer wrapping it.
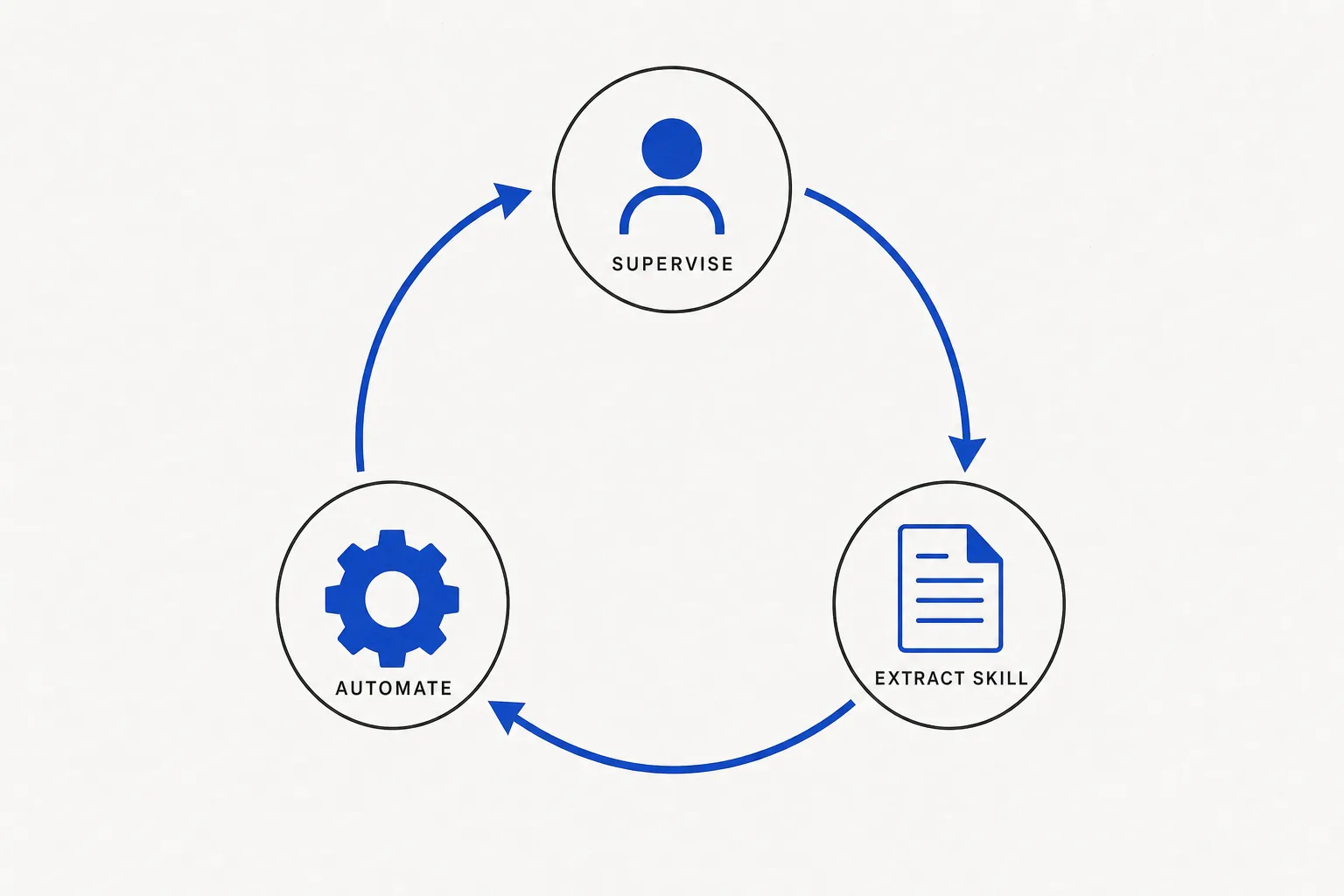
- Supervise the AI on a task. Run it live, watch what it does, correct where it drifts.
- When it works, ask it to create a skill. Say: “Write a skill file that captures this process — the reasoning, the steps, the edge cases.” This is a standing operating procedure the AI writes for itself. See the OpenClaw skills guide for the file format.
- Schedule the skill. “Run this every 24 hours.” Now it’s not you doing the task — it’s an autonomous loop.
- Repeat with the next task. Each skill you ship is capacity that compounds.
Why this works: token reasoning is designed to mimic human reasoning — connecting concepts, pattern-matching from prior context, stepping through problems. Andrej Karpathy has compared this to how human cognition develops. The implication is that the same management techniques that work with humans — clear SOPs, defined scope, feedback loops — work with AI. The difference is that AI doesn’t have coordination overhead, doesn’t forget the SOP, and scales horizontally without hiring.
Managing AI is the new management skill
A lot of my current job is reformulating what people send me and routing it to the right AI on my machine.
That sounds trivial. It’s not. The skill is knowing what each model and agent can do, when to delegate vs. when to do it yourself, and how to write a prompt that doesn’t need three rounds of correction. That’s the same skill set as managing a team — you wouldn’t expect the CMO to write code, and you shouldn’t expect GPT-4o to do the same job as a Claude Opus agent with a loaded context window.
50% of why people fail with AI is they don’t know what’s possible per model. They send complex reasoning tasks to the wrong tool, get bad output, and conclude AI doesn’t work.
What AI-fluent management actually looks like:
- You know which tasks each model handles well and where its failure modes are.
- You treat agents like junior hires: give them a tight scope, a clear SOP, and a feedback loop before you let them run unsupervised.
- You don’t batch all “AI work” to one tool. You route by task type — reasoning, writing, code, retrieval — the same way you’d route work across a team with different specializations.
- You measure token consumption, not hours. The metric for productivity is: how much work did we convert per dollar of tokens today?
If you want someone to run this audit for your team, the consulting page covers how I do it.
The org shape that survives the next 12 months
- AI workforce shares skills and memory — a “company brain” that every agent draws from. One agent builds a skill; all agents benefit. This is the harness at the org level.
- UI stays for humans. Users, affiliates, and partners still interact through interfaces designed for them. The AI layer is internal infrastructure.
- Per niche: 1 BD + 1 dev/AI manager + capital. BD handles human relationships. The dev manages AI quality, taste, and alignment — not necessarily by writing code, but by being close enough to the system to know when it’s right and when it’s drifting.
- Whitelabel software is dead within 12 months. Any company selling a software wrapper around a model that customers could access directly has 12 months to find a different moat.
- Partners will need to interact directly with the AI, not through a dashboard that abstracts it away. The value is in the AI’s judgment, not the UI around it. The partners who stay close to the AI will stay ahead.
Why most companies will stall
Most companies will spend the next 24 months losing slowly.
Not dramatically. They’ll still ship. They’ll still have clients. They’ll just get incrementally outpaced by the operations running on 10% of their headcount and 10x the throughput.
The four categories of stalling:
- Old-moat defenders. Companies whose value is lines of code, proprietary datasets, or IP that AI can replicate. They’ll fight the shift for 18 months and then do a frantic rebuild under duress.
- Politics-driven SaaS sellers. Exec gets taken to dinner, watches a beautiful slide deck, signs a $500K contract. Nobody uses the software. The operator below them implements 20% of what’s actually possible and declares success.
- AI-consultant implementers. Hire a consultant, run a 10-week assessment, implement 10% of the recommendations, call it an AI transformation. The consultant moves on; the initiative dies in the next reorg.
- Brand-politics buyers. EU companies signing with Mistral over Anthropic not because Mistral is better (it isn’t — by roughly 10x on most tasks) but because it’s French and they want to look right in a board meeting. The competitive compounding still happens to them; they just pretend it isn’t.
The ones who survive will fire half their team and rebuild on the new foundation. Elon did it. Jack did it. Brian Armstrong at Coinbase did it. The common pattern: a technical founder or exec with genuine authority who was willing to take the short-term political hit for the structural rebuild. Everyone else is still in committee.
Plan for 2× in 12 months
The next meaningful model release is June/July — Claude’s next major version. After that, the next doubling cycle targets late 2026 with Claude 5 and GPT 6. The reasonable planning assumption: the AI available to you in January 2027 will be roughly 2× more capable than what you’re running today.
That means:
- Structure your org now for what AI will do then, not today. If a task requires a human today because the AI isn’t quite good enough, assume that constraint is gone in 12 months and design the workflow without the human in it.
- The harness you build today is what determines how much of the 2026 model upgrade you capture. A team with no harness gets a better model; a team with a mature harness gets 2× output overnight.
- Every month you delay building harness is a month of compounding you’ll never recover. The math is exponential. The gap between teams that started 6 months ago and teams that start today is not 6 months — it’s closer to 3–4x in operational throughput.
When to hire me
If you want someone to run this audit on your specific operation — what’s automatable today, what harness to build first, what to kill — that’s what I do. See the consulting page or book a 30-minute discovery call.
— Yoann